

Ijraset Journal For Research in Applied Science and Engineering Technology
Sentiment Analysis on Online E-commerce Product Reviews using NLP
Authors: B Mohana Vamsi, R Manu Chandra Sai
DOI Link: https://doi.org/10.22214/ijraset.2024.58910
Certificate: View Certificate
Abstract
Online shopping is routine in day-to-day life, and the preponderance of products at home is mostly from online shopping. But we can’t test or check the quality of products in online shopping. In those circumstances, product reviews play a vital role in purchasers purchasing a product. Sentiment analysis of the product makes the customer identify the best quality product effortlessly and gives perfect decision-making for the product choice. However, people across countries who speak different languages might find it arduous to analyze the situation. We proposed a solution in which we can do both language identification, translation, and analysis of the text review data. Using a Google Language translator, we can identify and translate the language to any destination language that we want to analyze the text. VADER makes that analysis and gives us the best result for the product reviews. The experimental results of the proposed solutions were well-defined and established in sentiment analysis tasks.
Introduction
I. INTRODUCTION
The world has increased in just 20 years, so many inventions and discoveries have been recorded. Web 2.0 was an upgraded version of Web1.0, which most people depend on Web 2.0 which makes people's life easier. One of the Web 2.0 was online shopping, which was daily essential for people. Every product, such as hair pins, electronics, groceries, and Home appliances, is available in e-commerce shopping. E-commerce has been used in different categories, such as C2C (Customer to Customer), B2C (Business to Customer), and B2B (Business to Business).
Purchasing a product from e-commerce was challenging because of the virtual interaction between seller and buyer. We cannot see the product physically and check the quality of product through the online. In that case, every product has details, such as product features, quality, size, pictures of products, and customer reviews.
Customer reviews play a significant part in purchasing the product. Every review described the product, quality, and maintenance involved in purchasing the product by the customer. Product reviews are different in different aspects, such as Text reviews and Star reviews. Star-based reviews are central reviews that most people follow but cannot give a complete description of the product, but text-based reviews can give a complete description of the product and whether to buy the product or not.
Text-based reviews are the most critical reviews; people from different countries with different languages get involved in those text reviews. which gives the product a real nature; based on those reviews’ product can be reviewed for selling or discontinued. Analyzing those text-based reviews is tricky because of language; many people from different countries text in their language or common language (English). Nevertheless, researchers are done with single-language base product reviews, which can analyze the product reviews accurately. Analyzing text reviews is known as sentiment analysis, which involves significant aspects of the product's reputation. Recently, many researchers and scholars have studied sentiment analysis and come up with different solutions for different aspects of text analysis. They used different methodologies, algorithms, and solutions to analyze text-based sentences. Using Naive Bayes, we can get the sentiment analysis accuracy which can define the product's nature [3]. The neural network was also involved in sentiment analysis with different case scenarios [7].
In recent years, researchers preferred social information for the sentiment evaluation of people`s evaluations of a product, topic, or event [7], [9].These are the 3 primary instructions of a category in which every opinion is in its favored elegance primarily based totally on the outcomes received after processing it. Based on the study, many paintings have been completed on News, Twitter data, Amazon, and some others. Nevertheless, now it has protected online product opinions in its area too. Online-bought customers deliver their opinions in the shape of remarks and ratings. These opinions significantly assist the outlets and sellers describe the quality, appropriate and horrific factors of the products, and a few different factors.
So, critiques are taking up the advertising world. For this reason, a crucial element is to lessen the mistake and complexity of predicting the sentiment at the back of a review. In the Beyond era, extraordinary gadgets gaining knowledge of methods like Naïve Bayes, Logistic Regression, and SVM were used for sentiment evaluation which produced truthful results.
From the attitude of sentiment evaluation tools, this liberty to keep expression is an important challenge, because the intention is to extract the preoccupations of respondents in non-dependent data.
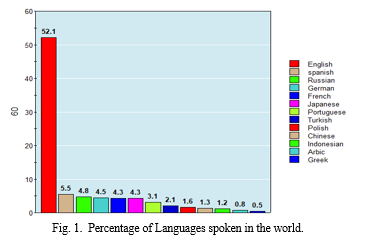
However, reviews are in different languages, and it took much work to analyze the sentiment of the products. It may be located from Figure 1 that English is utilized by 52.1% of Internet customers, observed via way of means of Spanish (5.5%) and German (4.8%), which make up 62.4% of customers of the Internet. The closing 37.6% of customers talk in different languages, consisting of Arabic, Indonesian, Malaysian, Portuguese, French, Hindi, Urdu, and others [13].
The fundamental trouble is that maximum of those non-English languages is aid-bad in device studying due to the small length of labeled datasets. This study makes a specialty of the Urdu language as a number one low-aid language and makes use of it for experiments at some point in the examination. To the excellence of our knowledge, presently to be had Urdu sentiment evaluation datasets presently have a low wide variety of instances, at a maximum of 11,000. Thus, this examination explores the device translation method to create a massive dataset for low-aid languages with the aid of virtually translating the English dataset into Urdu, German, and Hindi [13].
However, in this paper, we proposed a solution that translates the language into a destination language and sentiments those texts using an existing algorithm, i.e., the VADER algorithm. A semantic and rule-primarily based totally VADER changed into used to calculate polarity ratings and classify sentiments, which overcame the weak spot of manual labeling [11].
Using Google Translate NLP, we can translate the different text languages into the destination language, i.e., English was the destination language used to detect the sentiment analysis of the text reviews.
In sum, the contributions of this paper are threefold: (1) We show how semantic lexicon-based VADER can be used to sentiment those review texts. (2) We add knowledge on machine learning and NLP algorithms such as Naive Bayes, SVM, etc.., and the sentiment analysis of review texts. (3) We translate those reviews from the source language into the destination language using Google Translate NLP which can help us to translate those texts [11].
II. RELATED WORK
This section reviews the work done in text sentiment analysis from three aspects: sentiment analysis methods based on sentiment lexicon, sentiment analysis methods based on machine learning, and sentiment analysis methods based on deep learning.
The sentiment evaluation primarily based totally on device studying is essentially the text categorization task. Many annotated corpus are used for education to get a sentiment classifier. The sentiment classifier can decide textual content sentiment tendency. Sentiment analysis is a well-studied problem [15]. The most common sentiment analysis problem is classifying a text into either positive or negative polarity. Moreover, language-based sentiment analysis took much work to analyze the sentiment through the particular language and get a more accurate prediction.
Guixian Xu and Ziheng Yu et al. [2] were two researchers from The Minzu University of China who developed a method using the naïve Bayesian classifier for the Chinese text model to give more accurate results of the language preprocessing and sentiment of the language text. As a result, the naive Bayesian area classifier is used to categorize the textual content area wherein the polysemic sentiment phrase is, so the sentiment polarity of the phrase may be distinguished. The experimental consequences display that the sentiment type technique proposed in this technique has a terrific impact on the hotel, clothing, fruit, digital, and shampoo fields [2]. Zhi Li et al. [3] proposed a sentiment evaluation method from a video with different languages. They mainly focused on the Chinese language and extracted the sentiment analysis of the video text. Danmaku was the primary language. They concentrated on the language sentiment and used machine learning techniques like Naïve Bayes to get the polarity of the Danmaku text data.
Ruba Obiedat et al. [5] proposed a method called Arabic Aspect-Based Sentiment Analysis: A Systematic Literature Review, which focused on the sentiment analysis of the Arabic language text and used different techniques to sentiment the Arabic text for sentiment analysis aspect-based analysis. Sergey Smetanin [8] has proposed a model for the Russian language to sentiment the Russian language to enhance the exceptional of the carried-out sentiment evaluation research and to enlarge the present studies base to new directions. Additionally, to assist students pick the precise education dataset, he finished a further literature evaluation and recognized publicly to have sentiment datasets of Russian-language texts. Abdul Ghafoor et al. [13] proposed a solution that maximum herbal language processing tasks, together with polarity assessment, phrases translated through Google translator from one language to any other frequently extrude the meaning. It results in a polarity shift inflicting the system`s overall performance degradation, specifically for sentiment class and emotion detection tasks. They prefer Urdu as the primary language to detect the sentiment analysis of the language-based text analysis.
III. PROPOSED MODEL
The extensive goal of this project is to develop a solution that requires us to predict online product reviews in different languages. Sentiment analysis of text-based reviews gives a particular quality prediction of the product. Forecasts can be in other languages that have to change into destination source languages, enabling us to predict the actual meaning of the review and sentiment of the product. Indeed, this project includes some NLP algorithms that help translate different languages into a single language and the sentiment of the texts, which can give us a universal solution for the product review data.
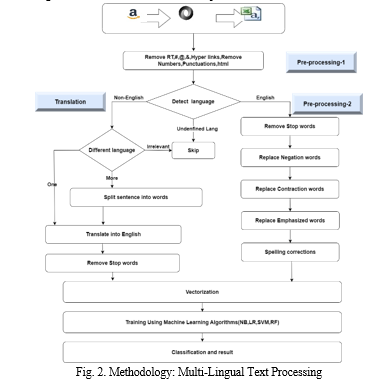
As we can see, the model's flowchart is related to the proposed model. Essential sentiment dictionary carries many sentiment phrases but omits a few phrases. Some sentiment phrases referred to as subject sentiment phrases are normally utilized in one unique subject, and the sentiment tendency of the sentiment phrases is remarkable.
Figure 2 illustrates the technique of multilingual textual content processing. The Amazon evaluates the dataset that was translated from Deutsch, French, Arabic, Chinese, etc., into English Utilizing Google Machine Translation API. All datasets are cut up into education and trying out the use of sci-kit-learn.7 Cross-validation and easy look-at educate cut are carried out wherein the educated set is used to educate the version and the look-at set to validate the version. Different devices getting to know, and deep getting-to-know fashions are used to educate and validate the version. Furthermore, if there are any incorrectly expected translated evaluations, they're translated manually to discover the language systems and constructs, moving the polarity of the machine-studying translated text. In the end, manually translated and machine-translated evaluations are as compared to discover language systems and constructs labeled as ambiguous words, idioms and phrases, negation, sarcasm, and slang [13].
IV. EXPERIMENTS AND ANALYSIS
Text preprocessing is a technique to smooth textual content information and make it geared up to feed information to the model. Text information carries noise in numerous bureaucracies like emotions, punctuation, and textual content in extraordinary cases. When we speak approximately Human Language, there are different methods to mention the identical thing, and that is most effective the principal trouble we should cope with due to the fact machines will now no longer apprehend words. They want numbers, so we want to transform textual content into numbers efficiently.
We collected the Amazon review data from the AWS bucket which has different languages such as Deutsch, French, Arabic, etc... We used those data to get our sentiment analysis for the texts. we imported some NLP libraries which were helpful to our sentiment analysis such as open multilingual wordnet, stop words, and Punkt.
Punkt is used to divide textual content right into a listing of sentences with the aid of the use of an unmanaged set of rules to construct a version for abbreviation phrases, collocations, and phrases that begin sentences. OMW helps find conceptual relationships between words such as hypernyms, hyponyms, synonyms, antonyms, etc.
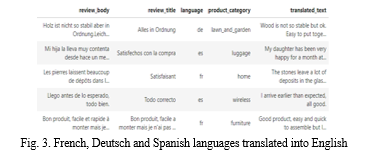
We imported the necessary data and transformed the CSV file into a dataset for text preprocessing. The Google Trans-New API from Google was applied to translate the assessment dataset from German, Urdu, Arabic, and French into English. Figure 4 demonstrates a pattern assessment in English and its corresponding translations in German, Urdu, and Hindi. The API takes two parameters as input, the source language text and the target language code. The code for the target language is entered as the second parameter. The language codes for Google Translation are available online. French, the code is "fr", for German, it is "de", and for Spanish, it is "es". [13].
translate(text; lang_tgt = code)
Google announced the launch of Google Translate in April 2006 based on the Phrase-Based Machine (PBMT) Translation algorithm. Later, in September 2016, Google announced that Google Translate was switching to a new translation system called Google Neural Machine Translation System (NMT). The PBMT method breaks the complete sentences into words and phrases and these terms are translated independently. Whereas NMT learns a mapping between the input language (sentence in input language) and output language (equivalent sentences in output language) [13].
After we use Google NLP, we start classifying the text using some NLP algorithms such as Naive Bayes, Logistic Regression, etc...


After all analysis and classifications, we used the Sentiment Intensity Analyzer NLP i.e., VADER (Valence Aware Dictionary and Sentiment Reasoner) Algorithm to find out the sentiment of the text data. For the analyzer, we divided the text data into subjectivity and polarity to find out the sentiment percentage of the text data.
Polarity assigns a positive or negative polarity score to each text instance based on the sentiment analysis results. A rating near 1 shows a wonderful sentiment, a rating near -1 shows a terrible sentiment and a rating near zero shows an impartial sentiment. Subjectivity assigns a subjectivity rating to each text instance based on the sentiment analysis results. A rating near 1 shows an excessive stage of subjectivity (i.e. primarily based totally on non-public critiques or feelings), whilst a rating near zero shows a low stage of subjectivity (i.e. based on information).
By combining the polarity and subjectivity scores, we obtain a more nuanced understanding of the sentiment of the text data. From Fig. 7, we can see that the subjectivity and polarity values state the score to find the sentiment of those translated text data.
V. EXPERIMENTAL RESULT
From Fig. 7, we can see that sentiment analysis for the translated text uses various metrics such as accuracy, precision, recall, and F1 score. These metrics offer an extra distinctive view of the model`s performance, which includes the cap potential to discover nice and poor instances, and the variety of fake nice and fake poor predictions made via way of means of the model. Also, we used the Wilson Lower bound to find the sentiment proportion for the text data.
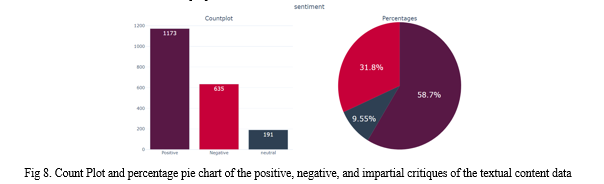
From Fig. 8 we can see that most of the reviews are positive reviews which have a maximum percentage of 58.7%, Negative reviews which have 31.8%, and Neutral reviews which have the lowest percentage i.e., 9.55%. From all the research, analysis, and classification reports we predicted the translated text data sentiments with an accuracy of 80% which is better accuracy than we figured from many researchers.
Conclusion
The enormous use of the Internet has come to be a day-by-day habit for plenty of people, for online purchasing and social networking programs inclusive of Facebook and Twitter. These programs provide a huge variety of features, inclusive of multilingual support, permitting customers to jot down and put up their language. However, this boom in the quantity of multilingual information has brought about a want for the correct processing of these records for significant insights. Despite this, there may be constrained studies targeted on a way to successfully technique multilingual textual content. In mild of this, this examination aimed to expand a system mastering version for a useful resource-wealthy language like English and use it on technique translated textual content from low-useful resource languages. Additionally, we explored the effect of translating textual content from a useful resource-wealthy language to a low-useful resource language via way of means of evaluating category consequences and engaging in blunders evaluation to perceive the phrase classes chargeable for any polarity shifts or overall performance degradation. For destiny work, researchers may also need to observe different translators, along with Microsoft Bing, and Apple Siri Translator, or create their own translator and examine the outcomes with Google Translator. It might be charming to assess the overall performance of lexicon-primarily totally based sentiment evaluation and transformer-primarily based totally fashions on textual content that has been routinely translated.
References
[1] Lei Wang, Jianwei Niu, and Shui Yu, “SentiDiff: Combining Textual Information and Sentiment Diffusion Patterns for Twitter Sentiment Analysis” at IEEE Transactions on Knowledge and Data Engineering Vol. 14, No. 8, August 2018, DOI 10.1109/TKDE.2019.2913641. [2] Guixian Xu, Ziheng Yu, Haishen Yao, Fan Li, Yuenting Meng, And Xu Wu, “Chinese Text Sentiment Analysis Based on Extended Sentiment Dictionary”, 2019 IEEE. Translations and content mining Vol 7, 2019, DOI 10.1109/ACCESS.2019.2907772 [3] Zhi Li, Rui Li, Guanghao Jin, “Sentiment Analysis of Danmaku Videos Based on Naïve Bayes and Sentiment Dictionary”, DOI 10.1109/ACCESS.2020.2986582, IEEE Access [4] Li Yang, Ying Li, Jin Wang and R. Simon Sherratt, “Sentiment Analysis for E-Commerce Product Reviews in Chinese Based on Sentiment Lexicon and Deep Learning”, Vol 8, 2020, DOI 10.1109/ACCESS.2020.2969854 [5] Ruba Obiedat, Duha AL-Darras, Esra Alzaghoul, and Osama Harfoushi, “Arabic Aspect-Based Sentiment Analysis: A Systematic Literature Review”, Vol 9, 2021, DOI 10.1109/ACCESS.2021.3127140 [6] Fuad Alattar and Khaled Shaalan, “Using Artificial Intelligence to Understand What Causes Sentiment Changes on Social Media”, Vol 9, 2021, DOI 10.1109/ACCESS.2021.3073657 [7] Faliang Huang, Xuelong Li, Changan Yuan, Shichao Zhang, Jilian Zhang, and Shaojie Qiao, “Attention-Emotion-Enhanced Convolutional LSTM for Sentiment Analysis”, IEEE Transactions on Neural Networks and Learning Systems, pp:2162-237X, 2021 IEEE, DOI 10.1109/TNNLS.2021.3056664 [8] Sergey Smetanin, “The Applications of Sentiment Analysis for Russian Language Texts: Current Challenges and Future Perspectives”, Vol 8, 2020, DOI 10.1109/ACCESS.2020.3002215 [9] Shihab Elbagir and Jing Yang, “Twitter Sentiment Analysis based on ordinal Regression”, DOI 10.1109/ACCESS.2019.2952127 [10] Pablo Sánchez-Núñez, Manuel J. Cobo, Carlos de las Heras-Pedrosa, José Ignacio Peláez, Enrique Herrera-Viedma, “Opinion Mining, Sentiment Analysis and Emotion Understanding in Advertising: A Bibliometric Analysis”, DOI 10.1109/ACCESS.2020.3009482 [11] Anny Mardjo and Chidchanok Choksuchat, “HyVADRF: Hybrid VADER–Random Forest and GWO for Bitcoin Tweet Sentiment Analysis”, Vol 10, 2022, DOI 10.1109/ACCESS.2022.3209662 [12] Fatima Es-Sabery, Ibrahim Es-Sabery, Abdellatif Hair, Beatriz Sainz-De-Abajo, and Begonya Garcia-Zapirain, “Emotion Processing by Applying a Fuzzy-Based Vader Lexicon and a Parallel Deep Belief Network Over Massive Data”, Vol 10, 2022, DOI 10.1109/ACCESS.2022.3200389 [13] Abdul Ghafoor, Ali Shariq Imran, Sher Muhammad Daudpota, Zenun Kastrati, Abdullah, Rakhi Batra, and Mudasir Ahmad Wani, “The Impact of Translating Resource-Rich Datasets to Low-Resource Languages Through Multi-Lingual Text Processing”, Vol 9, 2021, DOI 10.1109/ACCESS.2021.3110285 [14] Dan Wu, Daqing He, “A Study of Query Translation using Google Machine Translation System”, DOI: 10.1109/CISE.2010.5677008 [15] Qingxi Peng, Lan You, Qisheng Lu, and Xiangyu Li, “Mining Review Unit Model for Online Review Analysis”, Vol 8, 2020, DOI 10.1109/ACCESS.2020.3033820 [16] Huaqian He, Guijun Zhou, and Shuang Zhao, “Exploring E-Commerce Product Experience Based on Fusion Sentiment Analysis Method”, Vol 10, 2022, DOI 10.1109/ACCESS.2022.3214752
Copyright
Copyright © 2024 B Mohana Vamsi, R Manu Chandra Sai. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET58910
Publish Date : 2024-03-10
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online